字符编码小记
目录
概述
先从人类的通讯方式说起。在电报机出现之前,信息传递一般都是通过飞鸽传书、驿马邮递这些方式,然而这种方式非常耗时。直到19世纪,人类发明出了电报机,但是很尴尬的是电报机的信息是通过电信号传递,无法表示复杂的人类文字,于是出现了摩尔斯电码,通过点和划不同的排列顺序表示英文字母和数字。摩尔斯电码就是一种”编码”,跟字符编码很相似。
我们知道计算机是使用二进制的形式进行数据存储和传输的,因此计算机的设计者也使用了编码的方式来表示文字,比较常见的有ASCII、GB2312、Unicode等。

字符编码是什么
在介绍字符编码的原理前,首先需要讲清楚几个概念。先来看看摩尔斯电码,摩尔斯电码由点和划两种信号组成,我们要发送摩尔斯电码时,首先需要一张摩尔斯电码对照表。我们整理出要发送的信息,将信息的每个字按对照表的信号发送出去。
字符编码也是相似。但字符编码要复杂一些。每种字符编码都会有对应的一个字符集(Character set),字符集中每个字符有一个对应的码位(Code Point),可以理解为这个字符的编号。我们发送信息时,需要先在字符集中找到字符对应的编号,然后根据特定的规则把编码转换成二进制数字。这个过程称为编码(encoding)。
{kind=link}
下面我们来总结一下这几个概念:
字符编码
使用某种编码系统去表示一个字符集合的过程。
字符集
字符的集合
码位
某个字符在字符集中的数字编号。码位也可以有含义(如作为某种文本格式)
编码
将码位按一定的规则转换成二进制表示形式的过程。
解码
编码的逆过程
详解字符编码的过程
在这里我将列出两种字符编码的过程以便理解上面的概念。为了更好的理解,推荐使用hexdump以十六进制的形式查看文件。
ASCII
ASCII是单字节编码,ASCII使用了一个字节中的7位,剩下一位为0。ASCII不存在由code point转换为二进制形式的过程,因为它就是以code point存储。因此我们需要进行ASCII编码的时候,只需要从ASCII表中选择需要的字符,然后以字符对应的码位存储就完成了。
接下来我们验证一下。用任意编辑器创建一个内容为ascii test的文件,以ASCII编码存储。然后我们用hexdump查看该文件的内容(部分hexdump的工具会在开头显示位置号,在这里省略,另外hexdump会有多种输出的格式,这里以单字节为单位输出):
61 73 63 69 69 20 74 65 73 74 2e 0a
将ascii test按编码表转换为十六进制形式,正好与上面的输出相同。至于末尾的0a,是换行符,一般编辑器存储的时候会自动添加,在不同操作系统上默认的换行符是不同的。
UTF-8
在介绍UTF-8编码过程之前,要先讲一下Unicode和UTF-8的关系。Unicode是一个字符集,而UTF-8则是使用Unicode字符集的一种字符编码方式。具体来说,Unicode包含1,114,112个code point,而UTF-8、UTF-16、UTF-32等字符编码都使用同一个Unicode字符集,但是它们把code point转换成二进制的结果都不相同。此外,UTF-8只使用了Unicode字符集的其中一部分。 看看下图或者会更清楚,另外推荐一个查询unicode编码的网站
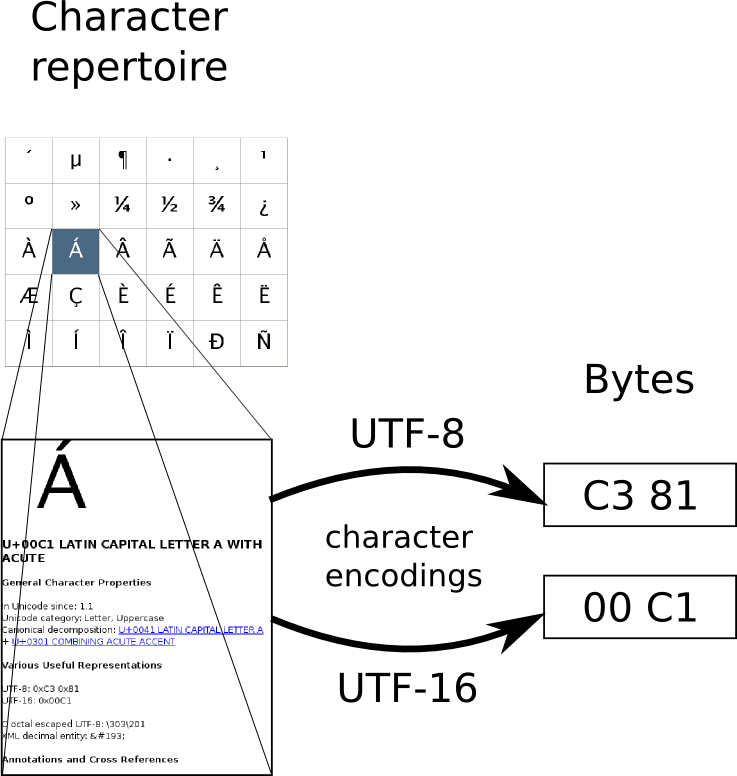
接下来将 详细讲解UTF-8编码,内容基于RFC3629,里面有一些细节这里不会展开,感兴趣可以看一下。UTF-8是一种变字节编码,以字节为单位,一个UTF-8字符经过编码后所占字节数不固定。如何分辨一个UTF-8字符占多少个字节,引用RFC的原话(经过翻译):
在UTF-8编码会将字符集U+0000至U+10FFFF编码为1-4个字节。 单字节的编码最高位为0,剩余的7位用于作为字符编码。 对于n字节的编码(n > 1),首个字节的n个高位为1,且紧跟着的后面一位为0,该字节的剩余所有位都用于作为字符编码。 而对于后面的字节,最高位为1,最高位后一位为0。 下表是不同字节形式的编码格式,其中x代表作为字符编码的位

对一个UTF-8字符进行编码的步骤如下:
- 从字符集中找到需要编码的字符,根据上表和字符的code point来判断最终的字节序占多少个字节。
- 从上表中选出对应的字节序列。
- 把码位填充进字节序列的x位当中,先填充最低位的字节,使用码位的最低位填充字节的最低位,然后依次把下一位填到字节的下一位。当填充完一个字节后,向下一个高位字节填充,以此类推,直到所有x位被填充完为止。
下面我举个例子说明这个编码的过程。
我要将中文字符的人转为UTF-8编码。首先我从unicode字符集找到人,查到其code point为4EBA,属于0000 0800 ~ 0000 FFFF的范围,因此人的编码是一个三字节编码,我们的字节序为1110xxxx 10xxxxxx 10xxxxxx。接下来我们开始填充这三个字节,4EBA转换到二进制为0100 1110 1011 1010,从低位开始填充:
# 原始字节序
1110xxxx 10xxxxxx 10xxxxxx
# 填充完最低位第一个字节
1110xxxx 10xxxxxx 10111010
# 填充完最低位第二个字节
1110xxxx 10111010 10111010
# 填充完最低位第三个字节
11100100 10111010 10111010
最终我们得到二进制形式11100100 10111010 10111010,转换为十六进制为E4 BA BA。现在赶紧打开你的编辑器,输入人之后以UTF-8保存,然后使用hexdump验证一下吧~
RFC中还有描述解码的过程,这里就不介绍了,至于BOM,我会放在后面的拓展部分。
字符编码的发展历史
字符编码的历史能搜出来一堆,我这里推荐一篇写的比较好的文章。
概括字符编码的发展历史,最早出现的应该是ASCII,基本满足了美国的使用需求。后来计算机在欧洲开始普及,于是欧洲人使用了ASCII编码中一个字节的第8位,扩展出了EASCII编码。计算机在中国普及的时候,中国起初定义了一套GB2312编码。但一段时间后发现有一些汉字并没有被收录,于是又出现了GBK编码,是GB2312的扩展。再后来GBK又扩展成GB18030,把少数民族的文字也收录进去了。然而台湾是使用繁体字的,所以台湾又有自己的一套BIG5编码。
到这里人们发现每个地方都自己弄了一套编码,结果谁也不兼容谁,应用软件还需要实现多编码的支持。因此国际组织就出手了,建立了一套Unicode字符集,目标是收录地球上所有的文字。
扩展
关于BOM
BOM全称是Byte order mark,说到BOM,首先得说一下UTF-16的编码方式,可以参考RFC2781。UTF-16的定义如下:
- code point在0x10000之前的字符直接用一个16位二进制数(也就是两字节)表示,数值与code point相同。
- code point在0x10000~0x10FFFF由两个连续的16位二进制数表示,第一个二进制数范围是0xD800~0xDBFF,接下来一个二进制数范围是0xDC00~0xDFFF。
- code point超过0x10FFFF的字符无法使用UTF-16编码。
由上面可以看出UTF-16的一个编码单位是两个字节的,这里就有一个问题了,在依次读入两个字节时,到底哪个是高位,哪个是低位?例如这里有两个UTF-16编码的字节4F和01,按不同的顺序就可能为4F01和014F,分别代表企和ŏ。因此就需要BOM来指定用的是哪种顺序了。BOM是一个或多个字节,会被添加到文件的开头,当编辑器在读取文本内容的时候,要先把BOM去掉再进行解码。
因为UTF-8的一个编码单位一个字节,因此BOM对UTF-8来说是无意义的,UTF-8的BOM都为EF BB BF,可加可不加。而对于UTF-16来说,假如字节序是Big-endian,BOM就是FE FF。若字节序是Little-endian,BOM就是FF FE。
Mysql与emoji
UTF8可编码的code point范围是0000 0000 ~ 0010 FFFF,编码后占1~4个字节,但是Mysql的utf8类型实际上只兼容1~3字节的utf-8编码。大部分emoji在unicode中的code point位于0001 0000 ~ 0010 FFFF 这个区域,编码后占4字节。因此大部分emoji是无法存入使用utf8编码类型的mysql数据库的,直到Mysql的5.5.3版本,才加入了utf8mb4编码类型,才能完全兼容UTF8编码。把Mysql的编码类型改成utf8mb4时的注意事项可以参考这篇文章。
参考资源
https://en.wikipedia.org/wiki/Hex_dump
https://www.w3.org/International/questions/qa-what-is-encoding
https://www.w3.org/International/articles/definitions-characters/
http://os.51cto.com/art/201503/467929.htm
http://djt.qq.com/article/view/658
http://unicode.org/faq/utf_bom.html
http://stackoverflow.com/questions/1273693/why-is-u-used-to-designate-a-unicode-code-point
http://www.ietf.org/rfc/rfc3629.txt
http://stackoverflow.com/questions/9310274/how-can-i-use-vim-to-convert-my-file-to-utf8
http://www.mclean.net.nz/ucf/
http://www.ietf.org/rfc/rfc2781.txt
https://mathiasbynens.be/notes/mysql-utf8mb4